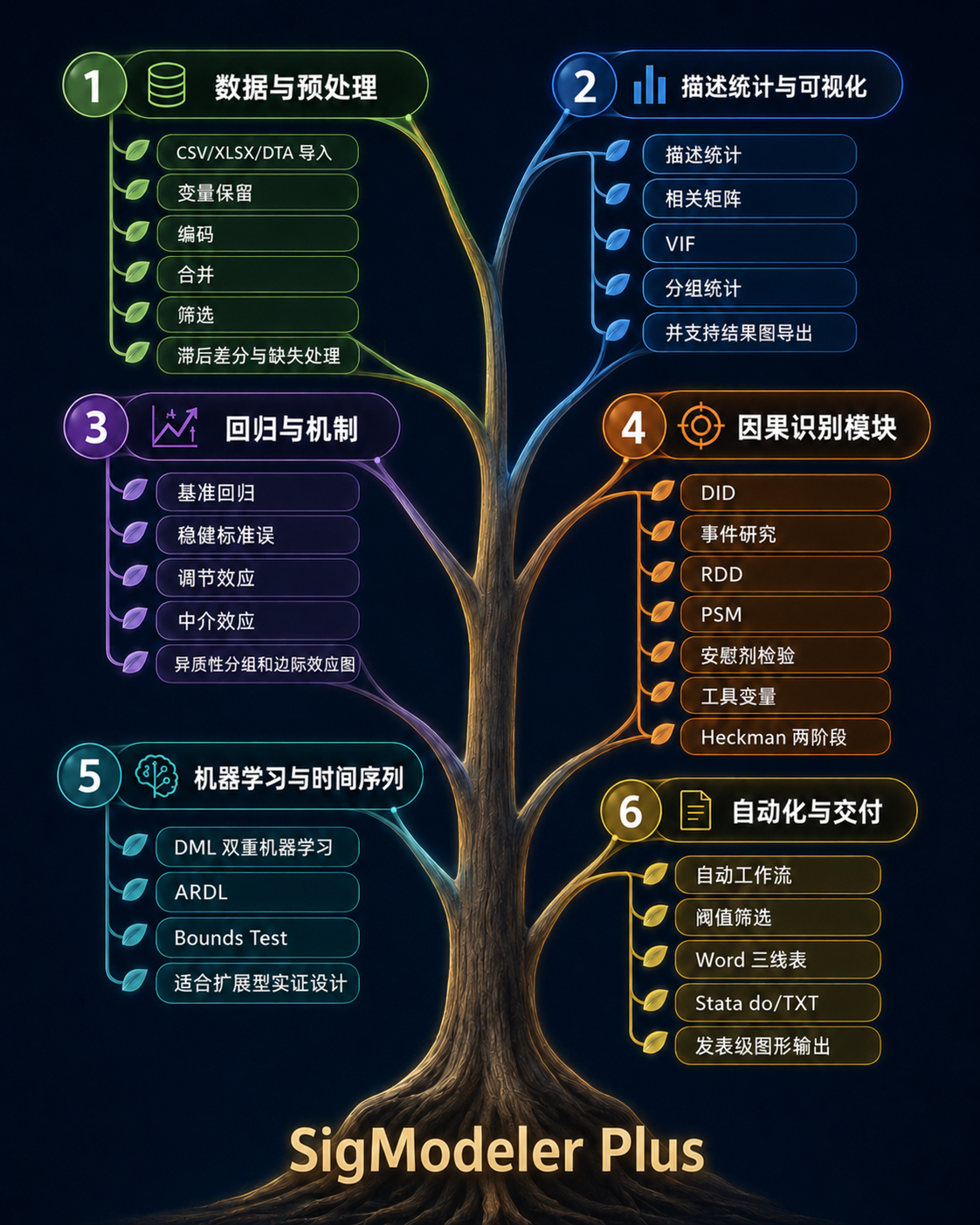
面向论文、报告和商业交付的完整计量工作台。Plus 版把数据预处理、描述统计、基准回归、DID/RDD/PSM/DML、内生性、机制检验、稳健性、时间序列和 Word/图形输出整合到同一条工作流里。
默认展示 Plus。切换版本后,功能、下载和界面预览会同步更新。
Windows 可下载;macOS 版本正在开发中。
Pro 和 Basic 使用订单码与机器码兑换激活码,流程保持原网站版本不变。
界面展示同样跟随版本切换。Plus 截图暂未上传,先保留占位。